
I like to order business cards from moo.com since they let you put photos on the back.
Here are the photos from the January 2015 order.













I like to order business cards from moo.com since they let you put photos on the back.
Here are the photos from the January 2015 order.
My presentation Building microservices with event sourcing and CQRS describes the challenges of functionally decomposing a domain model in a microservices based application. It shows that a great way to solve those problems is with an event-driven architecture that is based on event sourcing and CQRS.
The presentation uses a simple banking application, which transfers money between accounts, as an example. The application has the architecture shown in the following diagram:
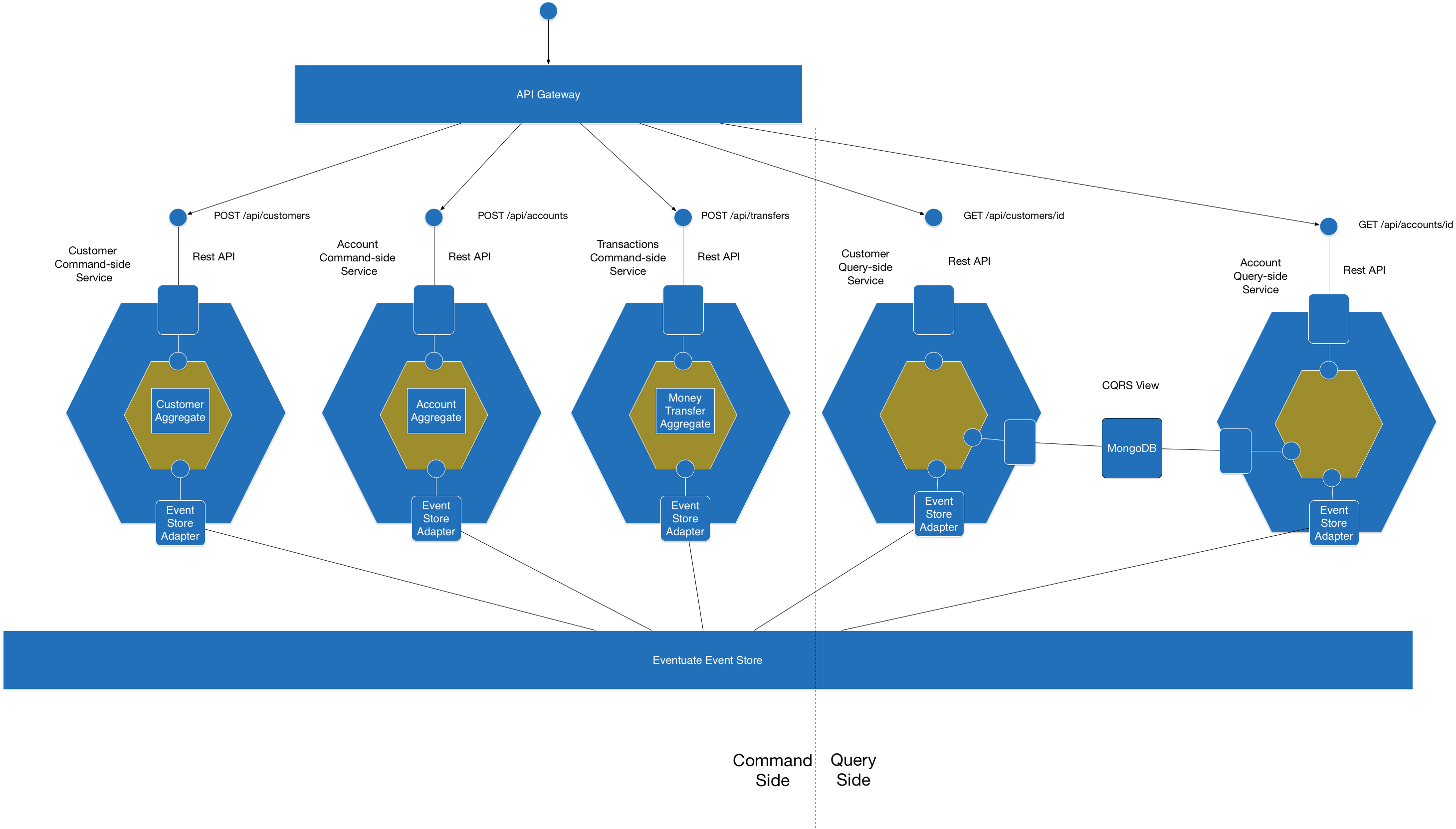
Banking application architecture
The application consists of four modules that communicate only via events and can be deployed either together in a monolithic application or separately as microservices.
The four modules are as follows:
You can find the source code and documentation for the example application in this github repository. There are currently two versions of the application: Java+Spring Boot and Scala+Spring Boot. I plan to publish a Scala/Play version shortly. The application uses a simple, embedded event store.
Watch the presentation (slides+video), and take a look at the source code and documentation. It would be great to get feedback on the programming model.
On Thanksgiving morning, I listened to a fascinating interview with Jacques Pepin, the celebrated French chef and PBS personality. Part of the interview touched on the topic of organic food. He joked that his parents were organic farmers even though at the time they were simply called farmers. That’s because the term ‘organic food’ didn’t exist until 1939. Before then all farming was organic. It wasn’t until the rise of industrialized agriculture, which uses pesticides, synthetic fertilizers, etc, that we needed a term to describe food grown without pesticides.
In many ways the organic food vs. food distinction mirrors the difference between microservices and service-oriented architecture (SOA). The term SOA has very negative connotations because it is strongly associated with commercialization and the baggage of WS* and ESBs. Consequently, in same way as we need to distinguish between organic food and food, we need to distinguish between microservices and SOA. It’s a shame that we need to do this because the word ‘microservices’ over-emphasizes service size.
In part 1 and part 2 of this series, we looked at the benefits of the microservice architecture and showed how Spring Boot simplifies the development of microservices. We also built a couple of simple Spring Boot-based services for user registration: a web application and a RESTful backend service (github repo). In this article, we will look at how to deploy Spring Boot-based services with an exciting new technology called Docker.
One of the neat things about Spring Boot is that it builds a self-contained, executable JAR file. We don’t need to install and correctly configure an application server. All that’s required is the appropriate version of Java. This means that you just need to tell whoever is responsible for deploying the application in production (or a QA environment) the JAR file along with the following information:
It’s straightforward to deploy an individual service. But deploying all of an application’s services is likely to be much more complicated. Different services might use different Java versions. For example, the Restful web service developed in part 1 used Java 7 where as the web application build in part 2 uses Java 8. Some services might be Play or Tomcat-based web applications. Services might not even be written in Java and instead use, for example, Ruby or NodeJS. The details of how each service is configured and run depend very much on the framework and language. Services might even have conflicting requirements. As a result, whoever is responsible to deploying an application in test and production environments has to deal with a lot of complexity.
The journey of services from development to production mirrors how cargo was shipped prior to the invention of intermodal shipping containers. At the origin, cargo was manually loaded one piece at a time onto the truck or train that carried it to the port. At the port of origin the cargo was unloaded onto the dock. Longshoremen then carefully loaded the tens of thousands of individual pieces of cargo one at time – boxes of bananas, ingots, coffee, etc. – onto the ship in a way that optimized space while simultaneously ensuring that the ship was stable. All of these steps then happened in reverse at the destination. Not only was shipping a time consuming and labor intensive process but repeated handling often broke fragile goods.
Containerization dramatically changed the ship industry (see the excellent book The Box for more details). All non-bulk cargo is now packed into standard shipping containers, which can be carried by truck, trains and ships. Crane operators now rapidly load and unload containers regardless of their contents. The contents of the container are never touched in transit. In other words, the shipping container encapsulates it’s contents. It has become the standardized API of cargo.
One way of containerizing a service is to package it as a VM machine image. For example, your continuous integration server can run a VM building tool such as Packer to create a VM image that can be deployed where needed. The virtual machine’s standardized API becomes the service’s management API. Starting and stopping the VM starts and stops the service regardless of the technology used to implement it. The contents of the VM are never touched. The service-as-a-VM approach is popular way of packaging and deploying services. For example, the Netflix video streaming service consists of many services each packaged as an AMI and deployed on Amazon EC2.
There are, however, various downsides to the service-as-a-VM approach. It assumes that your application runs in a virtualized environment, which is not always the case. Also, virtual machines are a heavyweight technology. It’s not practical to deploy more than a couple of VMs on a developer laptop. Building and booting an VM machine is usually I/O intensive and consequently slow. Also, some IaaS offerings such AWS EC2, don’t let you specify arbitrary VM sizes and so it’s likely that a given service doesn’t fully utilize its VM. Furthermore, the cost of deploying many small services as individual VMs on a public IaaS such as Amazon EC2 can rapidly add up.
Docker is a new way to containerize applications that is becomingly increasingly popular. It allows you to package a microservice in a standardized portable format that’s independent of the technology used to implement the service. At runtime it provides a high degree of isolation between different services. However, unlike virtual machines, Docker containers are extremely lightweight and as a result can be built and started extremely quickly. A container can typically be built in just a few seconds and starting a container simply consists of starting the service’s process(es).
Docker runs on a variety of platforms. It runs natively on Linux. You can also run Docker on Windows and Mac OSX using Boot2Docker, which runs the Docker daemon in a VirtualBox VM. Some clouds also have added extra support for Docker. For example, not only can you run Docker inside your EC2 instances but you can also use Elastic Beanstalk to run Docker containers. Amazon also recently announced the Amazon EC2 Container Service, which is a hosted Docker container management service. Google Cloud also has support for Docker.
The two main Docker concepts are image, which is a portable application packaging format, and container, which is a running image and consists of one or more sandboxed processes. Let’s first look at how images work.
A Docker image is read-only file system image of an operating system and an application. It’s analogous to an AWS EC2 AMI. An image is self-contained and will run on any Docker installation. You can create an image from scratch but normally an image is created by starting a container from existing base image, installing applications by executing the same kinds of commands you would use when configuring a regular machine, such as apt-get install –y and then saving the container as a new image. For example, to create an image containing a Spring Boot based application, you could start from a vanilla Ubuntu image, install the JDK and then install the executable JAR.
In many ways, building a Docker image is similar to building an AMI. However, while an AMI is a blob of bits, a Docker image has a layered structure that dramatically reduces the amount of time needed to build and deploy a Docker image. An image consists of a sequence of layers. When building an image, each command that changes the file system (e.g. apt-get install) create a new layer that references it’s parent layer.
This layered structure has two important benefits. First it enables of sharing of layers between images, which means that Docker does not need to move an entire image over the network. Only those layers that don’t exist on the destination machine need to be copied, which usually results in a dramatic speedup. Another important benefit of the layered structure is that Docker aggressively caches layers when building an image. When re-executing a command against an input layer Docker tries to skip executing the command and instead reuses the already built output layer. As a result, building an image is usually extremely fast.
A Docker container is a running image consisting of one or more sandboxed processes. Docker isolates a container’s processes using a variety of mechanisms including relatively mature OS-level virtualization mechanisms such as control groups and namespaces. Each process group has its own root file-system. Process groups can be assigned resource limits, e.g. CPU and memory limits. In the same way that a hypervisor divides up the hardware amongst virtual machines, this mechanism divides up the OS between process groups. Each Docker container is a process group.
Docker also isolates the networking portion of each container. When Docker is installed, it creates a virtual interface called docker0 on the host and sets up subnet. Each container is given it’s own virtual interface called eth0 (within the container’s namespace), which is assigned an available IP address from the Docker subnet. This means, for example, that a Spring Boot application running in a container listens on port 8080 of the virtual interface that’s specific to its container. Later on we will look how you can enable a service to be accessed from outside its container by setting up a port mapping that associates a host port with a container port.
It’s important to remember that even though an image contains an entire OS a Docker container often only consists of the application’s processes. You often don’t need to start any of the typical OS processes such as initd. For example, a Docker container that runs a Spring Boot application might only start Java. As a result, a Docker container has a minimal runtime overhead and its startup time is the startup time of your application.
Now that we have looked at basic Docker concepts let’s look at using Docker to package Spring Boot applications.
Let’s now build a Docker image that runs the Spring Boot application. Because Spring Boot packages the application as a self-contained executable JAR, we just need to build an image containing that JAR file and Java. One option is to take a vanilla Ubuntu Docker image, install Java and install the JAR. Fortunately, we can skip the first step because it’s already been done. One of the great features of the Docker ecosystem is https://hub.docker.com, which is a website where the community shares Docker images. There are a huge number of images available including dockerfile/java, which provides Java images for Oracle and OpenJDK versions 6, 7, and 8.
Once we have identified a suitable base image the next step is to build a new image that runs the Spring Boot application. You could build an image manually by launching the base image and entering shell commands in pretty much the same way that you would configure a regular OS. However, it’s much better to automate image creation. To do that we need to create a Dockerfile, which is a text file containing series of commands that tell Docker how to build an image. Once we have written a Dockerfile, we can then repeatedly build an image by running docker build.
Here is the Dockerfile (see github repo) that builds an image that runs the application
FROM dockerfile/java:oracle-java7 MAINTAINER chris@chrisrichardson.net EXPOSE 8080 CMD java -jar spring-boot-restful-service.jar ADD build/spring-boot-restful-service.jar /data/spring-boot-restful-service.jar
As you can see, the Dockerfile is very simple. It consists of the following instructions:
Here is the shell script that builds the image:
rm -fr build mkdir build cp ../build/libs/spring-boot-restful-service.jar build docker build -t sb_rest_svc .
This script builds the image using the docker build command. The –t argument specifies the name give to the new image. The “.” argument tells Docker to build the image using the current working directory as what is called the context of the build. The context defines the set of files that are uploaded to the Docker daemon and used to build the image. At the root of the context is the Dockerfile, which contains commands such as ADD that reference the other files in the context. We could specify the Gradle project root as the context and upload the entire project to the Docker daemon. But since the only files needed to build the image are the Dockerfile and the JAR it’s much more efficient to copy the JAR file to a docker/build subdirectory.
Now that have packaged the application as a Docker image we need to run it. To do that we use the docker run command:
docker run –d –p 8080:8080 --name sb_rest_svc sb_rest_svc
The arguments to the run command are as follows:
If we execute this command, the service starts up but the Spring application context initialization fails because it doesn’t know how connect to MongoDB and RabbitMQ.
Fortunately, this problem is easy to fix because of how Spring Boot and Docker support environment variables. One of the nice features of Spring Boot is that it let’s you specify configuration properties using OS environment variables. Specifically, for this service we need to supply values for SPRING_DATA_MONGODB_URI, which specifies the MongoDB database, and SPRING_RABBITMQ_HOST, which specifies the RabbitMQ host.
This mechanism works extremely well with Docker because you can use the docker run command’s –e option to specify values for a container’s environment variables. For example, let’s suppose that RabbitMQ and Mongo are running on a machine with an IP address of 192.168.59.103. You can then run the container with the following command:
docker run -d -p 8080:8080 -e SPRING_DATA_MONGODB_URI=mongodb://192.168.59.103/userregistration -e SPRING_RABBITMQ_HOST=192.168.59.103 --name sb_rest_svc sb_rest_svc
This command starts the service, which connects to MongoDB and RabbitMQ. You can examine the output of the process using the docker log command:
docker logs sb_rest_svc
This command outputs the stdout/stderr of the service.
In this article, we saw how containerization is an excellent way to simplify deployment. Rather than giving operations your application and detailed deployment instructions, you simply package your application as a container. Docker is an extremely lightweight and efficient container technology. You can package your services as Docker containers and run them unchanged in any Docker environment: development, test and production. Later articles will look at various aspects of deploying Docker-based applications including a Jenkins-based deployment pipeline that builds and tests Docker images. We will also look at using Docker to simplify the setup of test environments.
For some time now I’ve been running Docker-based dev and prod environments on Amazon EC2. Even though Docker is pretty new it works well and it’s a good platform for deploying microservice based applications. Each microservice is packaged as a Docker container, which provides a fast and convenient packaging and deployment mechanism regardless of which language and framework the microservice uses.
Over the weekend I finally upgraded my EC2 instances to use the latest version of Docker. I’d been meaning to do this for a while but there was a big obstacle: the EC2 instance running the Jenkins-based deployment pipeline was handcrafted :-(. I should have known better. It’s just that this particular server was created when I was getting started with Docker and so I had done a lot of configuration via the command line. Oops!
Upgrading to Docker consisted of creating some Chef cookbooks and a series of Packer templates that built AMIs using those cookbooks. I wrote three different Packer templates for building three different AMIs.
Since Jenkins home was on an EBS volume, it was trivial to shutdown the old CI server and attach the EBS volume to the newly created CI server. I then kicked off the deployment pipelines for all of the microservices in order to push their containers to the new S3-backed private registry.
Rebuilding prod servers starting from the Docker registry AMI was easy since I’d already written Chef cookbooks to do that. Moving the applications over simply consisted of pulling the containers from the private registry and launching them.
Now that I’ve automated AMI creation future upgrades should be trivial.
Write 100 times “I must not configure EC2 instances by hand”:
I must not configure EC2 instances by hand
I must not configure EC2 instances by hand
I must not configure EC2 instances by hand
….
Last week I gave a talk on functional programming at OSCON: Map, Flatmap and Reduce are Your New Best Friends: Simpler Collections, Concurrency, and Big Data.
Here are the slides:
You can also read about my visit to Portland Food Trucks.
In part 1 of this series, we looked at how the Microservice architecture pattern decomposes an application into a set of services. We described how Spring Boot simplifies the development of RESTFul web service within a microservice architecture. In this article we will look at developing a microservice that’s a traditional (i.e. HTML generating) Spring MVC-based web application. You will learn how Spring Boot simplifies the development of this kind of web application. You can find the example code on github.
We could implement an application’s server side-presentation tier as a single monolithic web application containing all of the Spring MVC controllers, views, etc. However, for large, complex applications we will very likely encounter the same kinds of problems with the monolithic architecture that were discussed in part 1. Consequently, it makes sense to apply the Microservice architecture pattern to the presentation tier and decompose it into a collection of web applications. Each web application implements the UI for one or more related stories or use cases. This enables the developers working on a particular part of the UI to independently develop and deploy their code.
In this article, we are going to implement the UI for the user registration example we discussed in part 1. The following diagram shows how the web application fits into the overall architecture.

The UI is implemented by a Spring-MVC based web application that invokes the RESTful API provided by the backend registration service. The UI consists of a registration page and a registration confirmation page, which are shown below:


The registration page consists of a form for entering the user’s email address and desired password. Clicking the “register” button POSTs to server, which responds by either redirecting the browser to the confirmation page or by redisplaying the form with error messages.
The registration page uses the JQuery validation plugin for browser-side validation and both pages use Bootstrap CSS for layout. Let’s now look at the Spring MVC components that handle the HTTP requests and generate HTML.
As you might expect, the Spring MVC-based presentation tier has a UserRegistrationController, which handles the HTTP requests, and a RegistrationRequest command class or form-backing object. The properties of the RegistrationRequest class, which correspond to fields of the registration form, have validation annotations that ensure that the email address appears to be valid and that the password meets the minimum length requirement.
class RegistrationRequest {
@BeanProperty
@Email
@NotNull
var emailAddress: String = _
@BeanProperty
@NotNull
@Size(min = 8, max = 30)
var password: String = _
}
Here is the Scala source code for the controller.
@Controller
class UserRegistrationController
@Autowired()(restTemplate: RestTemplate) {
@Value("${user_registration_url}")
var userRegistrationUrl : String = _
@RequestMapping(value = Array("/register.html"),
method = Array(RequestMethod.GET))
def beginRegister = "register"
@RequestMapping(value = Array("/register.html"),
method = Array(RequestMethod.POST))
def register(@Valid() @ModelAttribute("registration")
request: RegistrationRequest,
bindingResult: BindingResult,
redirectAttributes: RedirectAttributes): String = {
if (bindingResult.getErrorCount != 0)
return "register"
val response = try
restTemplate.postForEntity(userRegistrationUrl,
RegistrationBackendRequest(request.getEmailAddress,
request.getPassword),
classOf[RegistrationBackendResponse])
catch {
case e: HttpClientErrorException
if e.getStatusCode == HttpStatus.CONFLICT =>
bindingResult.rejectValue("emailAddress",
"duplicate.email.address",
"Email address already registered")
return "register"
}
response.getStatusCode match {
case HttpStatus.OK =>
redirectAttributes.addAttribute(
"emailAddress", request.getEmailAddress)
"redirect:registrationconfirmation.html"
}
}
@RequestMapping(value = Array("/registrationcomplete.html"),
method = Array(RequestMethod.GET))
def registrationComplete(@RequestParam emailAddress: String,
model: Model) = {
model.addAttribute("emailAddress", emailAddress)
"registrationconfirmation"
}
}
The controller has three methods that handle HTTP requests. The HTTP GET requests are handled by the beginRegister() method, which displays the registration page, and the registrationComplete() method, which redirects to the registration confirmation page.
The POST of the registration form is handled by the register() method. Spring MVC binds the form fields to method’s RegistrationRequest command parameter. The @Valid annotation on that parameter triggers validation of the command as defined by the validation annotations on the RegistrationRequest class. If form validation fails then the controller redisplays the registration form with one or more error messages.
Otherwise, if form validation succeeds, the controller makes a registration request to the web service that we built in part 1 of this series. The URL for the registration backend is injected into the controller using the @Value annotation on the userRegistrationUrl field.
If registration is successful (as indicated by an HTTP status of 200), the register() method then redirects to the confirmation page. Otherwise, if the call to the registration web service fails then the controller redisplays the registration form with one or more error messages.
In addition to the controller, the web application has views that generate HTML for the registration and confirmation pages. We could implement these views using JSPs. However, since Java 8 has an excellent JavaScript engine and today’s cool kids are using JavaScript-based templating frameworks this web application implements the views using DustJS. In a later article, we will describe the implementation of these DustJS views including how DustJS is integrated with Spring MVC.
The views generate HTML pages that use Bootstrap CSS and JQuery Validation JavaScript. Those pages also use application-specific CSS as well as some JavaScript that configures JQuery Validation to validate the registration form. With Spring Boot it’s remarkably easy to configure the web application to serve the necessary JavaScript and CSS. First, we will look at how to serve static assets for Bootstrap and the JQuery Validation plugin. After that we will look at how to serve application-specific JS and CSS files.
There are a couple of different ways to serve up CSS and JavaScript for Bootstrap and JQuery validation. One option is for the HTML to reference a content delivery network (CDN). While a CDN is great for production, it’s an obstacle for offline development. Another option is to manually download those files and configure Spring MVC to serve them as static content. While this isn’t too difficult, it typically means downloading multiple files – including transitive dependencies – from multiple sites, which is quite tedious.
A newer and much more convenient approach is to use WebJars. WebJars are client-side libraries (e.g. CSS and JavaScript) packaged as JAR files and published to a Maven repository. To use a particular client-side library you need to add the corresponding WebJar as a Gradle/Maven project dependency and configure Spring MVC to serve it as static content.
In order to use Bootstrap CSS and the JQuery validation plugin, the pom.xml for the registration web application has the following dependencies:
<dependency>
<groupId>org.webjars</groupId>
<artifactId>bootstrap</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.webjars</groupId>
<artifactId>jquery-validation</artifactId>
<version>1.11.1</version>
</dependency>
But that’s all we need to do since a very nice feature of Spring Boot is that detects these WebJars on the classpath and, by default, serves their contents under the path /webjars/**. The HTML pages can reference the CSS and JavaScript files as follows:
<html> … <link rel="stylesheet" href="webjars/bootstrap/3.1.1/css/bootstrap.css"> … <script src="webjars/jquery/2.1.0/jquery.js"></script> <script src="webjars/jquery-validation/1.11.1/jquery.validate.js"></script> …
Notice that jquery.js is available as static content even though it was not explicitly defined as a webjar dependency. That’s because the JQuery WebJar is a dependency of the JQuery validation WebJar and so Maven treats it as a transitive dependency.
Spring Boot also makes it easy to serve application-specific CSS and JavaScript files. It configures Spring MVC to treat a /static directory on the classpath as containing static content. Consequently, we can simply put the application-specific CSS and JavaScript files in the src/main/resources/static directory and the HTML pages can access them as follows:
<link rel="stylesheet" href="styles/main.css">
…
<script src="js/registration.js"> </script>
The CSS styles/main.css file is served from src/main/resources/static/styles/main.css and the js/registration.js file is served from src/main/resources/static/js/registration.js
Let’s now look at the other Spring Boot-related parts of the application: the Maven pom.xml and a Java configuration class.
This application is built using Maven because the Gradle Scala plugin currently doesn’t work with Java 8. The following listing shows the Spring Boot related parts of the Maven pom.xml:
<project>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.0.1.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
…
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
…
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>1.0.1.RELEASE</version>
</plugin>
…
</plugins>
…
</build>
The pom specifies that its parent pom is spring-boot-starter-parent, which is a special Spring Boot starter that defines use Maven defaults.
The pom.xml defines a dependency on the Spring Boot spring-boot-starter-web starter artifact, which ensures that we get a consistent set of dependencies to build this web application including various Spring framework and embedded Tomcat artifacts. The spring-boot-starter-web artifact also enables the Spring Boot’s auto-configuration.
In addition, the pom.xml defines a dependency on the Spring Boot spring-boot-starter-test starter artifact. This artifact pulls in artifacts for automated tests including the Spring framework’s spring-test artifact and some Spring Boot specific test classes.
The pom.xml also specifies the Spring Boot maven plugin, which is responsible for building the executable jar.
Since the application uses Spring Boot, it needs remarkably little configuration. There isn’t even a web.xml. Instead, there is a single configuration class:
@Configuration
@EnableAutoConfiguration
@ComponentScan
class UserRegistrationConfiguration {
@Bean
@Primary
def scalaObjectMapper() = new ScalaObjectMapper
@Bean
def dustViewResolver = {
val resolver = new DustViewResolver
resolver.setPrefix("/WEB-INF/views/")
resolver.setSuffix(".dust")
resolver
}
@Bean
def restTemplate = {
val restTemplate = new RestTemplate()
restTemplate.getMessageConverters foreach {
case mc: MappingJackson2HttpMessageConverter =>
mc.setObjectMapper(scalaObjectMapper())
case _ =>
}
restTemplate
}
}
This configuration class defines three beans:
This class defines the main() method that runs the application. It’s a one liner that calls the SpringApplication.run() method passing in the configuration class and the args parameter to main().
object UserRegistrationMain {
def main(args: Array[String]) : Unit =
SpringApplication.run(
classOf[UserRegistrationConfiguration], args :_ *)
}
The SpringApplication class is provided by Spring Boot. It’s run() method creates and starts the web container that runs the application.
We can build the application by running the ‘mvn package’ command:
$ mvn package [INFO] Scanning for projects... [INFO] --- maven-jar-plugin:2.3.1:jar (default-jar) @ spring-boot-user-registration-webapp --- [INFO] Building jar: /Users/cer/src/microservices-examples/spring-boot-webapp/target/spring-boot-user-registration-webapp-1.0-SNAPSHOT.jar … INFO] --- spring-boot-maven-plugin:1.0.1.RELEASE:repackage (default) @ spring-boot-user-registration-webapp --- [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------
We can then run the application using the java –jar command:
$ java -jar target/spring-boot-user-registration-webapp-1.0-SNAPSHOT.jar … 2014-04-25 16:38:36.599 INFO 29547 --- [ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 8080/http 2014-04-25 16:38:36.602 INFO 29547 --- [ main] n.c.m.r.main.UserRegistrationMain$ : Started UserRegistrationMain. in 4.931 seconds (JVM running for 5.816)
By applying the Microservice architecture pattern to the presentation tier we decompose what would otherwise be a large monolithic web application into many smaller web applications. Each web application implements the UI for one or more related stories or use cases. The example web application described in this article implements a user registration UI and registers users by making REST requests to a backend service. Because it’s a standalone service, the developers working on the registration UI can develop new features, fix bugs and deploy the changes independently of the rest of the system.
Spring Boot significantly simplifies the development and deployment of web applications. Because it provides Convention-over-Configuration in the form of auto-configuration, web applications need very little explicit configuration. There is no web.xml. Spring Boot configures Spring MVC to serve any WebJars on the classpath as static content. It also configures Spring MVC to treat a /static directory on the classpath as static content. As a result, you can focus on developing your web application.
Spring Boot also simplifies how you deploy your web application. The Spring maven (and Gradle) plugin packages your web application as an executable jar file containing an embedded Tomcat (or Jetty) server. You can run the jar file on any machine with Java installed – no need to install and configure an application server.
In later posts, we will look at other aspects of developing microservices with Spring Boot including automated testing and using DustJS in a Spring MVC application, as well as look at how Spring Boot simplifies monitoring and management.
This article introduces the concept of a microservice architecture and the motivations for using this architectural approach. It then shows how Spring Boot, a relatively new project in the Spring ecosystem can be used to significantly simplify the development and deployment of a microservice. You can find the example code on github.
Since the earliest days of Enterprise Java, the most common way of deploying an application has been to package all the application’s server-side components as a single war or ear file. This so-called monolithic architecture has a number of benefits. Monolithic applications are simple to develop since IDEs and other tools are oriented around developing a single application. They are also simple to deploy since you just have to deploy the one war/ear file on the appropriate container.
However, the monolithic approach becomes unwieldy for complex applications. A large monolithic application can be difficult for developers to understand and maintain. It is also an obstacle to frequent deployments. To deploy changes to one application component you have to build and deploy the entire monolith, which can be complex, risky, time consuming, require the coordination of many developers and result in long test cycles. A monolithic architecture can also make it difficult to trial and adopt new technologies and so you are often stuck with the technology choices that you made at the start of the project.
To avoid these problems, a growing number of organizations are using a microservice architecture. The application is functionally decomposed into a set of services. Each service has a narrow, focused set of responsibilities, and is, in some cases, quite small. For example, an application might consist of services such as the order management service, the customer management service etc.
Microservices have a number of benefits and drawbacks. A key benefit is that services are developed and deployed independently of one another. Another key benefit is that different services can use different technologies. Moreover, since each service is typically quite small, it’s practical to rewrite it using a different technology. As a result, microservices make it easier to trial and adopt new, emerging technologies. One major drawback of microservices is the additional complexity – development, and deployment – of distributed systems. For most large applications, however, the benefits outweigh the drawbacks.
You can learn more about microservices by visiting microservices.io.
Let’s imagine that you are implementing user registration as part of an application that has a micro-service architecture. Users register by entering their email address and a password. The system then initiates an account creation workflow that includes creating the account in the database and sending an email to confirm their address. We could deploy the user registration components (controllers, services, repositories, …. etc.) as part of some other service. However, user registration is a sufficiently isolated chunk of functionality and so it makes sense, to deploy it as a standalone micro-service. In a later blog post, we will look at the web UI part of user registration but for now we will focus on the backend service. The following diagram shows the user registration service and how it fits into the overall system architecture. 
The backend user registration service exposes a single RESTful endpoint for registering users. A registration request contains the user’s email address and password. The service verifies that a user with that email address has not previously registered and publishes a message notifying the rest of the system that a new user has registered. The notification is consumed by various other services including the user management service, which maintains user accounts, and the email service, which sends a confirmation email to the user.
It’s quite straightforward to implement the user registration backend using various projects in the Spring ecosystem. Here is the Spring framework controller, which is written in Scala, that implements the RESTful endpoint.
@RestController
class UserRegistrationController @Autowired()(…) {
@RequestMapping(value = Array("/user"),
method = Array(RequestMethod.POST))
def registerUser(@RequestBody request: RegistrationRequest) = {
val registeredUser =
new RegisteredUser(null,
request.emailAddress, request.password)
registeredUserRepository.save(registeredUser)
rabbitTemplate.convertAndSend(exchangeName, routingKey,
NewRegistrationNotification(registeredUser.id,
request.emailAddress, request.password)
RegistrationResponse(registeredUser.id, request.emailAddress)
}
@ResponseStatus(value = HttpStatus.CONFLICT,
reason = "duplicate email address")
@ExceptionHandler(Array(classOf[DuplicateKeyException]))
def duplicateEmailAddress() {}
}
The @RestController annotation specifies that Spring MVC should assume that controller methods have an @ResponseBody annotation by default.
The registerUser() method records the registration in a database and then publishes a notification announcing that a user has registered. It calls the RegisteredUserRepository.save() method to persist a new registered user. Here is the RegisteredUserRepository, which provides access to the database of user registrations.
trait RegisteredUserRepository extends MongoRepository[RegisteredUser, String]
case class RegisteredUser(
id : String,
@(Indexed@field)(unique = true) emailAddress : String,
password : String)
Notice that we do not need to supply an implementation of this interface. Instead, Spring Data for Mongo creates one automatically. Moreover, Spring Data for Mongo notices the @Indexed annotation on the emailAddress parameter and creates a unique index. If save() is called with an already existing email address it throws a DuplicateKeyException, which is translated by the duplicateEmailAddress() exception handler into an HTTP response with a status code of 409 (Conflict).
The UserRegistrationController also uses Spring AMQP to notify the rest of the application that a user has registered:
class UserRegistrationController @Autowired()(…) {
…
rabbitTemplate.convertAndSend(exchangeName, routingKey,
NewRegistrationNotification(registeredUser.id,
request.emailAddress, request.password))
…
}
case class NewRegistrationNotification(
id: String, emailAddress: String, password: String)
The convertAndSend() method converts the NewRegistrationNotification to JSON and sends a message to the user-registrations exchange.
So far, so good! With just a few lines of code we have implemented the desired functionality. But in order to have a complete deployable application there are a few more things we need to take care of.
And, oh yes, we had better write some tests.
The Spring framework provide three main ways of configuring dependency injection: XML, annotations, and Java-based configuration. My preferred approach is to use a combination of annotations and Java-based configuration. I avoid XML-based configuration as much as possible unless it is absolutely necessary.
We could just launch an IDE, annotate the classes, and write the Java configuration classes and before long we would have a correctly configured application. The trouble with this old-style approach of manually crafting the each application’s configuration is that we regularly create new microservices. It would become quite tedious to create very similar configurations over and over again even if we did just copy and paste from one service to another.
Similarly, to deploy the service, we could install and configure Tomcat or Jetty to run this service. But once again, in the course of building many microservices, this is something we would have to do repeatedly. There needs to be better way of dealing with both application and web container configuration that avoids all this duplication. We need an approach that lets us focus on getting things done for both web and non-web (e.g. message-based) applications.
One technology that lets you focus on getting things done is one of the newer members of the Spring ecosystem: the Spring Boot project. This project has two main benefits. The first benefit is that Spring Boot dramatically simplifies application configuration by taking Convention over Configuration (CoC) in Spring applications to a whole new level. Spring Boot has a feature called auto-configuration that intelligently provides a set of default behaviors that are driven by what jars are on the classpath. For example, if you include database jars on the classpath then Spring Boot will define DataSource and JdbcTemplate beans unless you have already defined them. As a result, it’s remarkably easy to get a new micro-service up and running with little or no configuration while preserving the ability to customize your application.
The second benefit of Spring Boot is that it simplifies deployment by letting you package your application as an executable jar containing a pre-configured embedded web container (Tomcat or Jetty). This eliminates the need to install and configure Tomcat or Jetty on your servers. Instead, to run your micro-service you simply need to have Java installed. Moreover, the executable jar format provides uniform and self-contained way of packaging and running JVM applications regardless of type, which simplifies operations. If necessary, you can, however, configure Spring Boot to build a war file. Let’s illustrate these features by developing a Spring Boot version of the user registration microservice.
The Spring Boot part of the application consists of four pieces: a build.gradle (or Maven pom.xml), one or more Java Configuration classes, a configuration properties file, which defines connection settings for the message broker and Mongo database, and a main() method class. Let’s look at each one in turn.
The build.gradle file configures the Spring Boot build plugin, which creates the executable jar file. The build.gradle file also declares dependencies on Spring Boot artifacts. Here is the file.
buildscript {
repositories {
maven { url "http://repo.spring.io/libs-snapshot" }
mavenCentral()
}
dependencies {
classpath("org.springframework.boot:spring-boot-gradle-plugin:1.0.0.RC5")
}
}
apply plugin: 'scala'
apply plugin: 'spring-boot'
dependencies {
compile "org.scala-lang:scala-library:2.10.2"
compile 'com.fasterxml.jackson.module:jackson-module-scala_2.10:2.3.1'
compile "org.springframework.boot:spring-boot-starter-web"
compile "org.springframework.boot:spring-boot-starter-data-mongodb"
compile "org.springframework.boot:spring-boot-starter-amqp"
testCompile "org.springframework.boot:spring-boot-starter-test"
testCompile "org.scalatest:scalatest_2.10:2.0"
}
repositories {
mavenCentral()
maven { url 'http://repo.spring.io/milestone' }
}
The Spring Boot build plugin builds and configures the executable war file to execute the main() method defined in the project.
What’s particularly interesting about build.gradle is that it defines dependencies on Spring Boot starter artifacts. Starter artifacts (aka. starters) use the naming convention spring-boot-starter-X, which X is the type of application that you are building. By depending on a starter you get a consistent set of dependencies for building applications of type X along with the appropriate auto-configuration behavior.
Since this service is a web application that uses MongoDB and AMQP, it defines the dependencies on the following starters:
All of these starters also depend on spring-boot-starter, which provides auto-configuration, logging, and YAML configuration file supports.
A typical Spring Boot application needs at least one Spring bean annotated with @EnableAutoConfiguration, which enables auto-configuration. For example, the Spring Boot Hello World consists of a single class that’s annotated with both @Controller and @EnableAutoConfiguration. Since the user registration service is more complex it has a separate Java Configuration class.
@Configuration
@EnableAutoConfiguration
@ComponentScan
class UserRegistrationConfiguration {
import MessagingNames._
@Bean
@Primary
def scalaObjectMapper() = new ScalaObjectMapper
@Bean
def rabbitTemplate(connectionFactory : ConnectionFactory) = {
val template = new RabbitTemplate(connectionFactory)
val jsonConverter = new Jackson2JsonMessageConverter
jsonConverter.setJsonObjectMapper(scalaObjectMapper())
template.setMessageConverter(jsonConverter)
template
}
@Bean
def userRegistrationsExchange() = new TopicExchange("user-registrations")
}
The UserRegistrationConfiguration class has three annotations: @Configuration, which identifies the class as a Java Configuration class, @EnableAutoConfiguration, which was discussed above, along with @ComponentScan, which enables component scanning for the controller.
The UserRegistrationConfiguration class defines three custom beans:
There is remarkably little configuration for this kind of application. That’s because Spring Boot’s auto-configuration creates several beans for you:
This class defines the main() method that runs the application. It’s a one liner that calls the SpringApplication.run() method passing in the configuration class and the args parameter to main().
object UserRegistrationMain {
def main(args: Array[String]) : Unit =
SpringApplication.run(classOf[UserRegistrationConfiguration], args :_ *)
}
The SpringApplication class is provided by Spring Boot. It’s run() method creates and starts the web container that runs the application.
This file contains property settings that define how the application connects to the RabbitMQ server and the MongoDB database. It currently defines one property:
spring.data.mongodb.uri=mongodb://localhost/userregistration
This property specifies that the application should connect to the Mongo host running locally on the default port and use the userregistration database rather than the default test database.
This default configuration can be overridden in a couple of different ways. One option is to specify properties values on the command line when running the application. The other option is to supply additional application.properties files, which override all or some of the properties. This is done using either system properties or by putting the files in the current directory or on the classpath. See the documentation for the exact details on how Spring Boot locates properties files.
With these two files and two classes, we can now build the application. Running ./gradlew build compiles the application, builds the executable jar and runs the tests. You can then execute the jar file to start the application:
$ java -jar build/libs/spring-boot-restful-service.jar … 2014-03-28 09:20:13.423 INFO 57472 --- [ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 8080/http 2014-03-28 09:20:13.426 INFO 57472 --- [ main] n.c.m.r.main.UserRegistrationMain$ : Started UserRegistrationMain. in 5.44 seconds (JVM running for 6.893)
Once built, this jar can move through the deployment pipeline to production. You can, for example, change the MongoDB connection URL by specifying the property on the command line:
$ java -jar build/libs/spring-boot-restful-service.jar \ --spring.data.mongodb.uri=mongodb://productionMongo/userregistration
Quite remarkable, given how little effort was required! Don’t forget to look at the code on github.
As you can see, Spring Boot lets you focus on developing your microservices. It dramatically reduces the amount of application and server configuration that you would normally need to write. Furthermore, it’s extremely easy to build an executable jar file that can be run on any machine with Java installed – no need to install and configure an application server. In later posts, we will look at other aspects of developing microservices with Spring Boot including web application development (see part 2 of this series), and automated testing, as well as look at how Spring Boot simplifies monitoring and management.
I’ve been giving talks on what are now called microservices for the past two years. The big idea is that in some situations rather than building a monolithic application (e.g. application = one huge WAR file) you should apply the Scale Cube (specifically y-axis splits aka. functional decomposition) and design your application as a collection of independently deployable services.
I have often introduced the idea as “SOA light” since you are building a service-oriented architecture. The trouble with the term SOA, however, is that it is associated with a lot of baggage: SOAP, ESBs, heavyweight ceremony, etc. Instead, I’ve talked about “Decomposing the monolith” or “Decomposing the WAR”. I’ve also used the term modular, polyglot architecture but that’s a bit of a mouthful.
At Oredev 2012, I encountered Fred George who was giving a talk on what he called microservices, which was a variant of what I had been talking about. What was especially intriguing about his approach was about how it pushed things to the extreme with a very heavy emphasis on very small services. The term microservices along with the idea of tiny 100 LOC services has got a fair amount of buzz recently. Martin fowler blogged about microservices and there has been some discussion on twitter.
On the one hand, I like the term microservices. It’s short and it catchy. The problem, however, is that it IMHO places excessive emphasis on smallness. After all, as I described at the start of this post the big idea is to break up the otherwise monolithic application into smaller, more manageable services by applying function decomposition. Some of those services can be just a few lines of code. For example, in one of my sample applications I have a 12 line Sinatra service that responds to SMS messages. While some services can be this small, others will need to be a lot larger. And that’s just fine. It all depends. Partitioning an application is a tricky design problem that has to balance a large number of constraints. To paraphrase Einstein, “Services should be made as small as possible, but no smaller.”
Last week I gave a couple of talks related to micro-services architecture at DevNexus 2014. The first talk was NodeJS: the good parts? A skeptic’s view (slides), which describes the pros and cons of JavaScript and NodeJS and how NodeJS is useful for building small-ish I/O intensive services such as API gateways and web applications.
The second talk was Futures and Rx Observables: powerful abstractions for consuming web services asynchronously (slides). This talk first describes how Scala Futures (and forthcoming JDK 8 CompletableFutures) can be used to greatly simplify API gateway code that needs to call multiple backend services concurrently. The talk then describes how Rx Observables (i.e. RxJava) are a more general purpose concurrency abstraction that can be also used to process asynchronous event streams.

